Nathan Louis

I am a research engineer at Southwest Research Institute, specializing in AI-applied human biomechanics research. My current interest involves understanding the dynamics of human motion though vision and physics simulation.
I completed my Ph.D. at the University of Michigan, Ann Arbor under the guidance of Jason J. Corso. My graduate research was focused on extracting physically grounded information from video and relating it to quantifiable skill. This ranges from tracking hand and human body poses, estimating external forces from human motion, and ranking the quality of actions.
selected publications
-
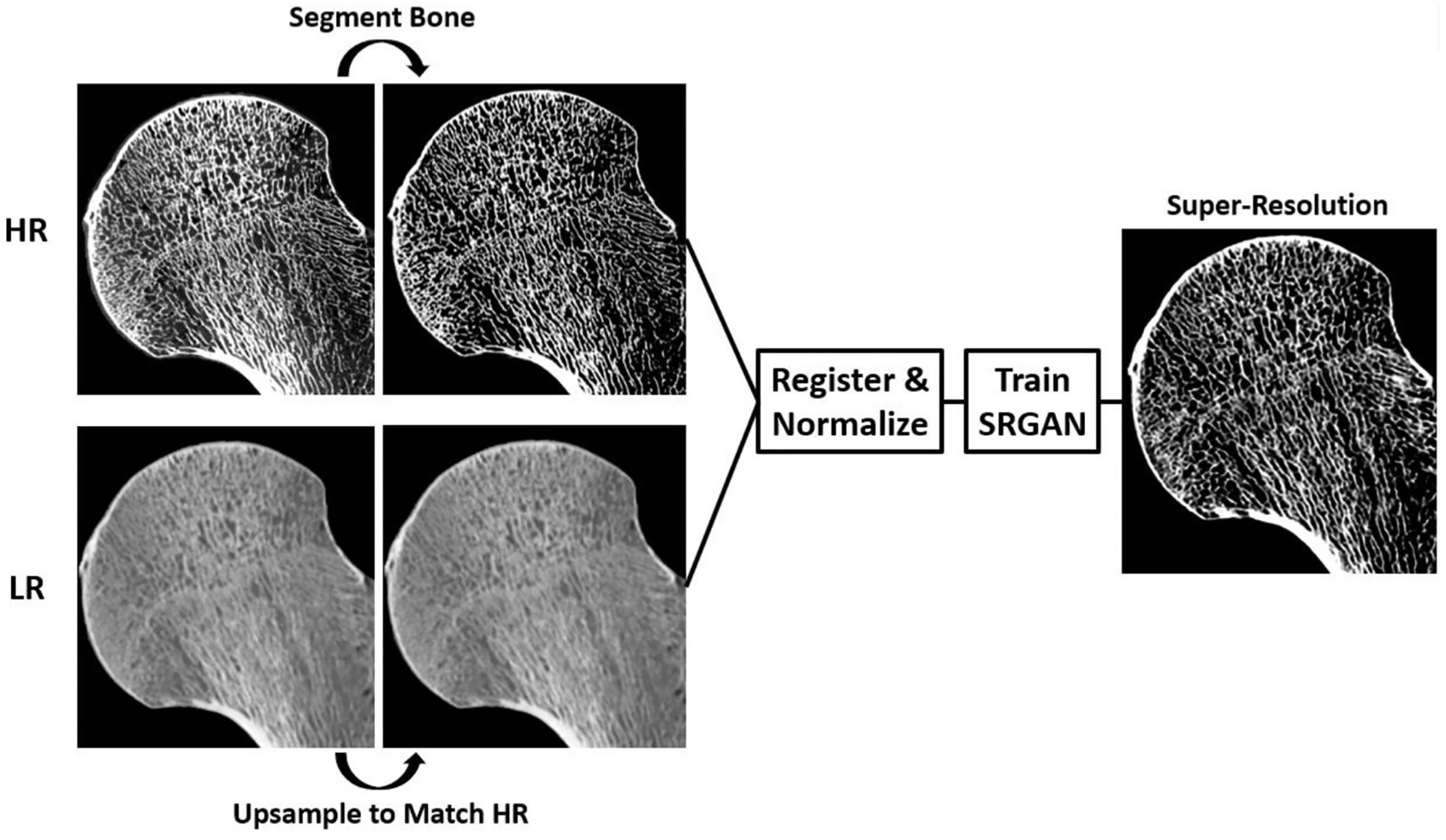 Super-resolution of clinical CT: Revealing microarchitecture in whole bone clinical CT image dataBone, 2024
Super-resolution of clinical CT: Revealing microarchitecture in whole bone clinical CT image dataBone, 2024